trac timeline 统计对任务单添加的评论
要求组员将任务单的进度及时的更新
但是timeline默认不统计新增 comment 操作的
开启很简单:
gvim trac.ini
找到
[timeline]
修改
ticket_show_details = true
tuxedo 打印buffer内容
昨天有其它省的同事问,我竟然一下子想不起来了.
做个记录.
与其它系统联调的时候很有用,也可以做为证据
//日志,累加内容
FILE *fp1;
fp1 = fopen("./fml_buffer.log","a+");
Ffprint32(rcvbuf,fp1);
fclose(fp1);越来越不喜欢上班了
不是其他的,主要是因为作息的原因.
7:30 基本是最困的时候,不得不挣扎着爬起来上班.
9:30 到公司了,也吃完东西,上完厕所,开始犯困了.好想睡回笼觉阿
11:30 肚子饿了
12:30 吃完饭,开始犯困了,想睡觉
2:00 困到极点了,估计不得不爬在那个典型人体工程学的反面教材的桌子上靠一下.然后会被压迫的胃和快断的颈椎弄醒.
3:30 还是困,半痴呆中,而且有点饿.
4:30 非常饿,如果能找到东西吃,那么吃饱了就会开始犯困.如果找不到东西吃,就会持续在找东西吃的饥饿驱动下,基本无法思考.
5:30 痴呆,麻木,上了一天班,累了,等下班吧.
......
20:00 之后,精神,效率,体能狂彪.到00:00 涨停..缓慢下降直到 凌晨 4:00犯困.
可以看出,整个上班的时间,都是我体能最差,注意力最差,不是犯困就是发呆,不然就是肚子饿的状态.
精力最充沛,注意力最集中,创造力最强的这段时间,我不得不洗洗刷刷,然后强迫的把自己压在床上,闭上眼睛睡觉,否则第二天会是地狱...
和生物钟无关,和作息无关. 不仅仅我有这种感觉
总觉得愚笨的人类设定的工作时间是不合理的.也许上帝都看得无奈:这些sb,工作时间设错啦!~~
也许应该学学galeki, 4点睡觉 中午12点起来.这样才是最优方案.
这种作息只有当自由工作者才有可能吧.
oracle sql 取连续数段
-
需求
表结构如下,作了简化
CREATE TABLE "INVOICE"."POOL"
(
"TAX_NBR" VARCHAR2(20 BYTE),--税务发票号
"STAFF_ID" NUMBER(20,0),--工号
)
tax_nbr 为税务发票号,staff_id 为持有该发票号的工号. tax_nbr在一段内连续.
要求统计时,按工号持有的号段统计出来
可能有这样的数据:
staff_id tax_nbr 1 1 1 2 1 3 1 7 1 8 1 9
要求统计出:
staff_id tax_begin_nbr tax_end_nbr 1 1 3 1 7 9
-
思路一
写程序把每条记录按顺序取出,比较每条是否等于上一条+1,不等于,那就反回一条统计.
然后接着比较......
-
思路二
一条select sql 就搞定了
SELECT staff_id, min(tax_nbr), max(tax_nbr)
FROM (SELECT staff_id,
tax_nbr,
TO_NUMBER(tax_nbr) -
(ROW_NUMBER() OVER(PARTITION BY staff_id ORDER BY TO_NUMBER(tax_nbr))) DIF
FROM pool)
GROUP BY staff_id, DIF;wxpython 读书笔记(0.15)读取目录 生成树状结构图
啄木鸟上面有还在翻译的:http://wiki.woodpecker.org.cn/moin/WxPythonInAction
wxpython中第15节有树状控件说明
- 加入节点
# -*- coding:UTF-8 -*-
import wx
class TestFrame(wx.Frame):
def __init__(self):
wx.Frame.__init__(self, None, title="simple tree", size=(400,500))
# Create the tree
self.tree = wx.TreeCtrl(self)
# Add a root node
rootID = self.tree.AddRoot("根节点")
# Expand the first level
self.tree.Expand(rootID)
app = wx.App()
frame = TestFrame()
frame.Show()
app.MainLoop()
# -*- coding:UTF-8 -*-
import wx
class TestFrame(wx.Frame):
def __init__(self):
wx.Frame.__init__(self, None, title="simple tree", size=(400,500))
# Create the tree
self.tree = wx.TreeCtrl(self)
# Add a root node
rootID = self.tree.AddRoot("根节点")
childID1 = self.tree.AppendItem(rootID, "子节点1级")
# Expand the first level
self.tree.Expand(rootID)
app = wx.App()
frame = TestFrame()
frame.Show()
app.MainLoop()
# -*- coding:UTF-8 -*-
import wx
class TestFrame(wx.Frame):
def __init__(self):
wx.Frame.__init__(self, None, title="simple tree", size=(400,500))
# Create the tree
self.tree = wx.TreeCtrl(self)
# Add a root node
rootID = self.tree.AddRoot("根节点")
childID1 = self.tree.AppendItem(rootID, "子节点1级")
childID2 = self.tree.AppendItem(childID1, "子节点2级")
# Expand the first level
self.tree.Expand(rootID)
app = wx.App()
frame = TestFrame()
frame.Show()
app.MainLoop()
- 取出目录以及子目录数据
os.listdir(dirname):列出dirname下的目录和文件
# -*- coding:UTF-8 -*-
import wx
import os
class TestFrame(wx.Frame):
def __init__(self):
wx.Frame.__init__(self, None, title="simple tree", size=(400,500))
# Create the tree
self.tree = wx.TreeCtrl(self)
# Add a root node
rootID = self.tree.AddRoot("根节点")
for i in os.listdir('/home/bigzhu'):
childID1 = self.tree.AppendItem(rootID, i)
self.tree.Expand(rootID)
app = wx.App()
frame = TestFrame()
frame.Show()
app.MainLoop()
# -*- coding:utf-8 -*-
import wx
import os
def appendDir(tree, treeID, sListDir):
"""遍历路径,将文件生成节点加入到wx的tree中
tree wx的tree
treeID 上级treeID
sListDir 一个绝对路径,会自动遍历下面的子目录
"""
#有些目录没有权限访问的,避免其报错
try:
ListFirstDir = os.listdir(sListDir)
for i in ListFirstDir:
sAllDir = sListDir+"/"+i
#有些目录名非法,无法生成节点,只有try一把
try:
childID = tree.AppendItem(treeID, i)
except:
childID = tree.AppendItem(treeID, "非法名称")
#如果是目录,那么递归
if os.path.isdir(sAllDir):
appendDir(tree, childID, sAllDir)
except:
pass
class TestFrame(wx.Frame):
def __init__(self):
wx.Frame.__init__(self, None, title="simple tree", size=(400,500))
# Create the tree
self.tree = wx.TreeCtrl(self)
# Add a root node
rootID = self.tree.AddRoot("根节点")
#appendDir(self.tree,rootID, "/home/bigzhu/code")
appendDir(self.tree, rootID, "/home/bigzhu/Desktop")
self.tree.Expand(rootID)
app = wx.PySimpleApp()
frame = TestFrame()
frame.Show()
app.MainLoop()gvim warning invalid input string 的解决办法
ubuntu 10.04 下
在 terminal 里起 gvim
刷出一堆
(gvim:2000): Gtk-WARNING **: Invalid input string
不影响 vim 的使用,但是会把 terminal 的内容刷的看不到了,而且很烦
报这个 warning 是因为 gtk2 对字体限制严格
原本的字体可以用 locale 来查看
发现 LANG 是 zh_CN.utf8 ,改成 zh_CN.UTF-8 就可以
~/.profile 里面添加一句
LANG=zh_CN.UTF-8
就没有那样不停弹出了
天空之城mv
希望ccav不要再非法用来做煽情的背景音乐了
完全被ccav玷污了这种感觉
不过感觉最好的还是在动画片里,女孩从天而落那段.
mv和其比起来还是有些逊色.
trac 日期格式出错
最近给小组人员搭建 trac 用作任务管理,发现 trac 0.12 国际化后,有一个 bug:
时间线或其它用地方有日期的地方是这样的:
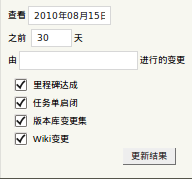
看起来还不错,都是中文,但是一查询就报错了:

是一个无效日期,或者日期格式未知。请尝试 "YYYY年MM月DD日"
临时解决办法:
启动 trac 前执行
export LC_TIME="en_US.utf8"
就会是如下的显示方式:
08/13/2010
错误是不报了,查也可以查了
问题是和中文习惯的反过来了
目前没找到更好的办法.
AIX 下 查看 cpu 占用
topas 以后
按几下 c 可以看到每个 cpu 的占用

 ,参见
,参见